Autonomous AI research agents aim to accelerate scientific discovery by automating the research pipeline,
from hypothesis generation to peer review. However, existing benchmarks rarely test a fundamental bottleneck:
whether Large Language Models can judge the methodological viability of a research idea
before expending time and computational resources. We introduce
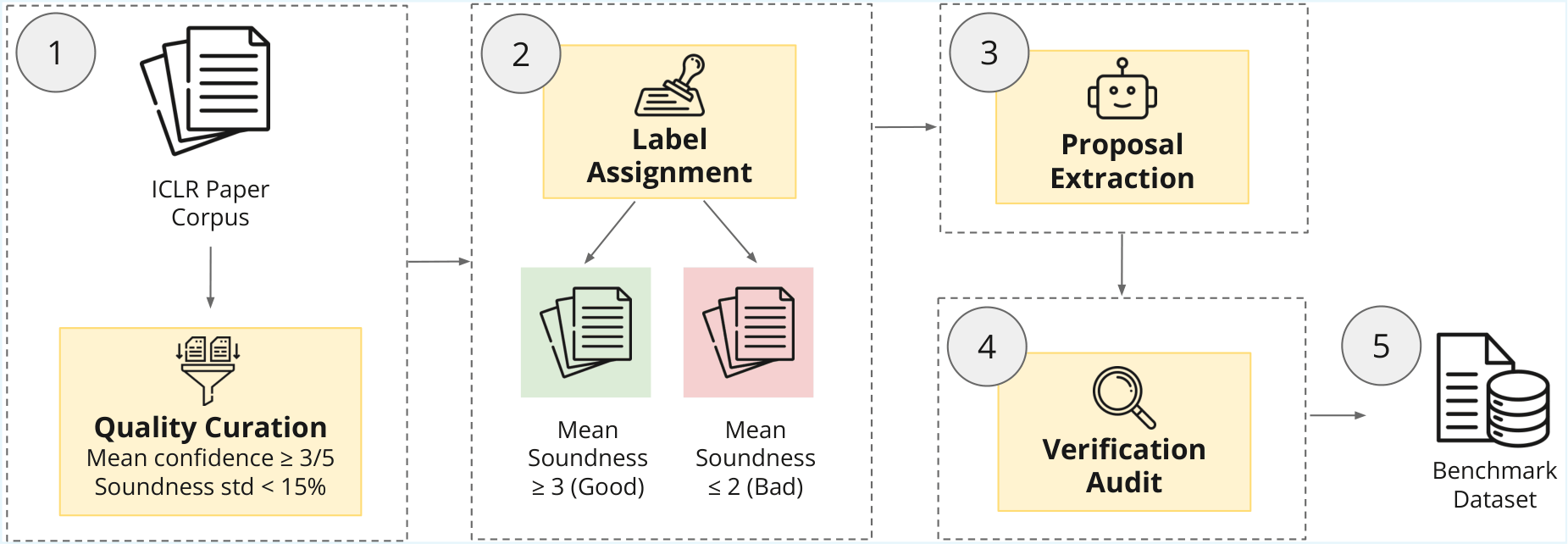
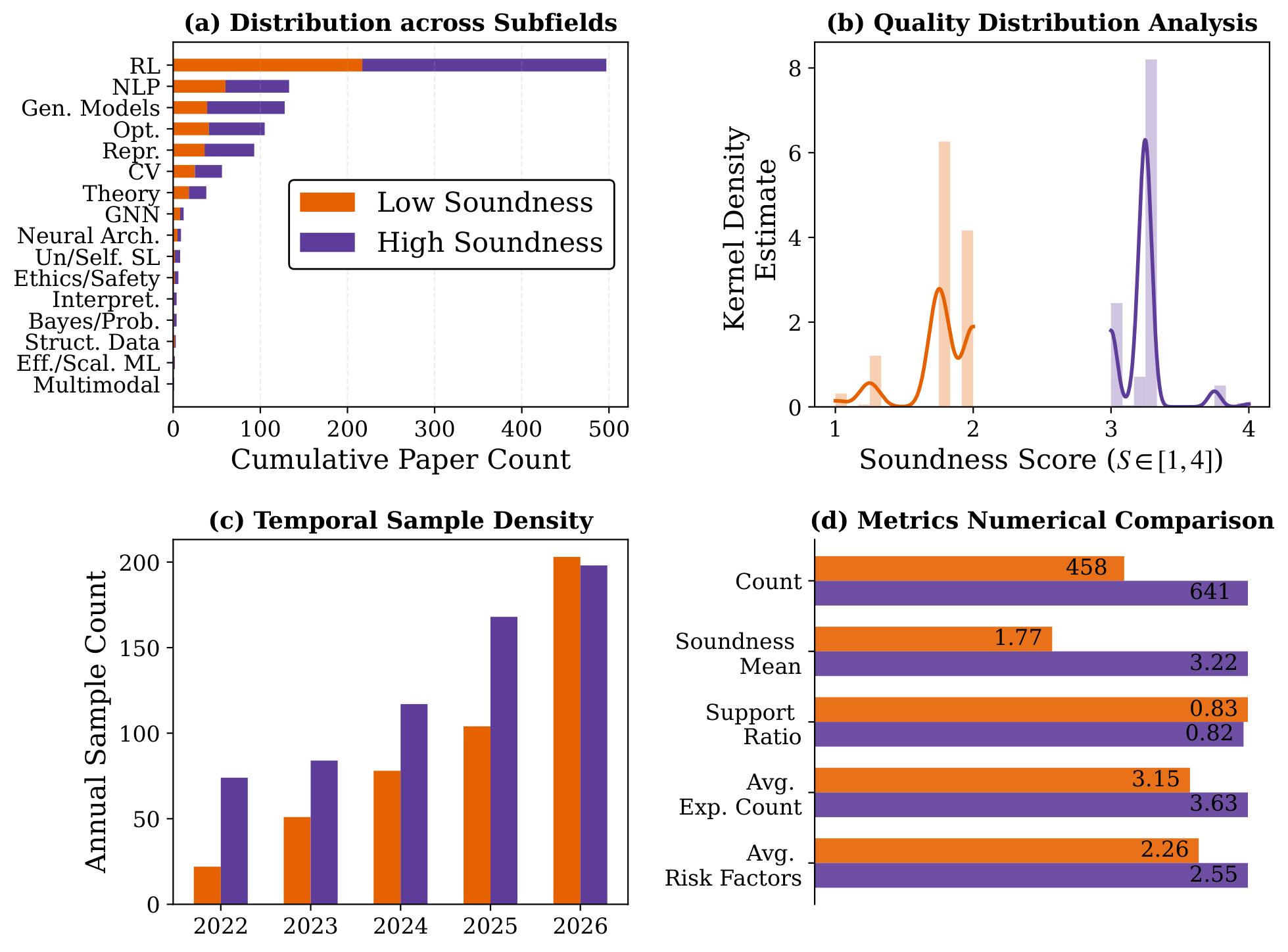
SoundnessBench, a curated benchmark of 1,099 machine-learning research proposals
reconstructed from ICLR submissions, labeled with reviewer soundness sub-scores, and audited against source
papers. SoundnessBench should be interpreted as a benchmark for recoverable proposal-stage soundness rather
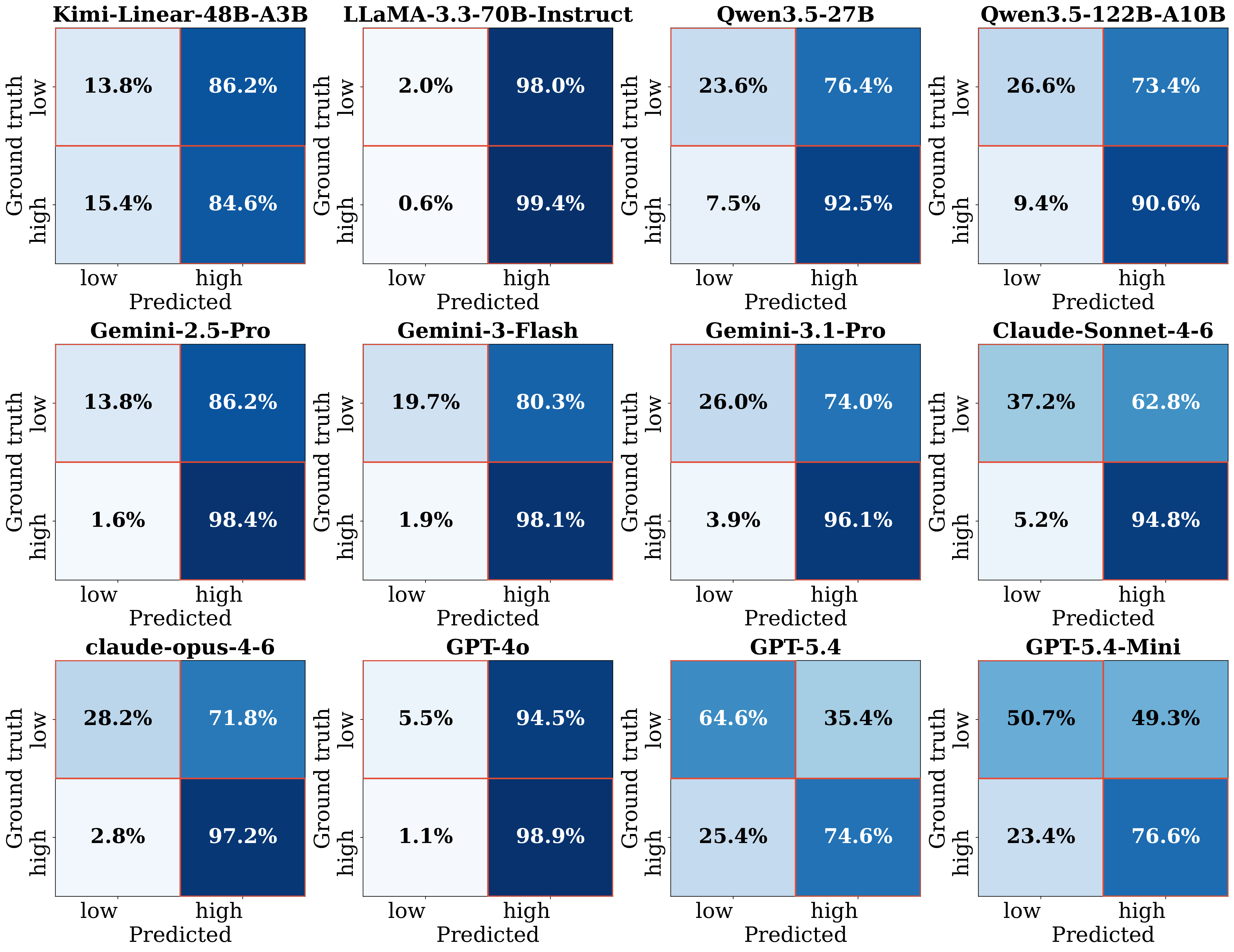
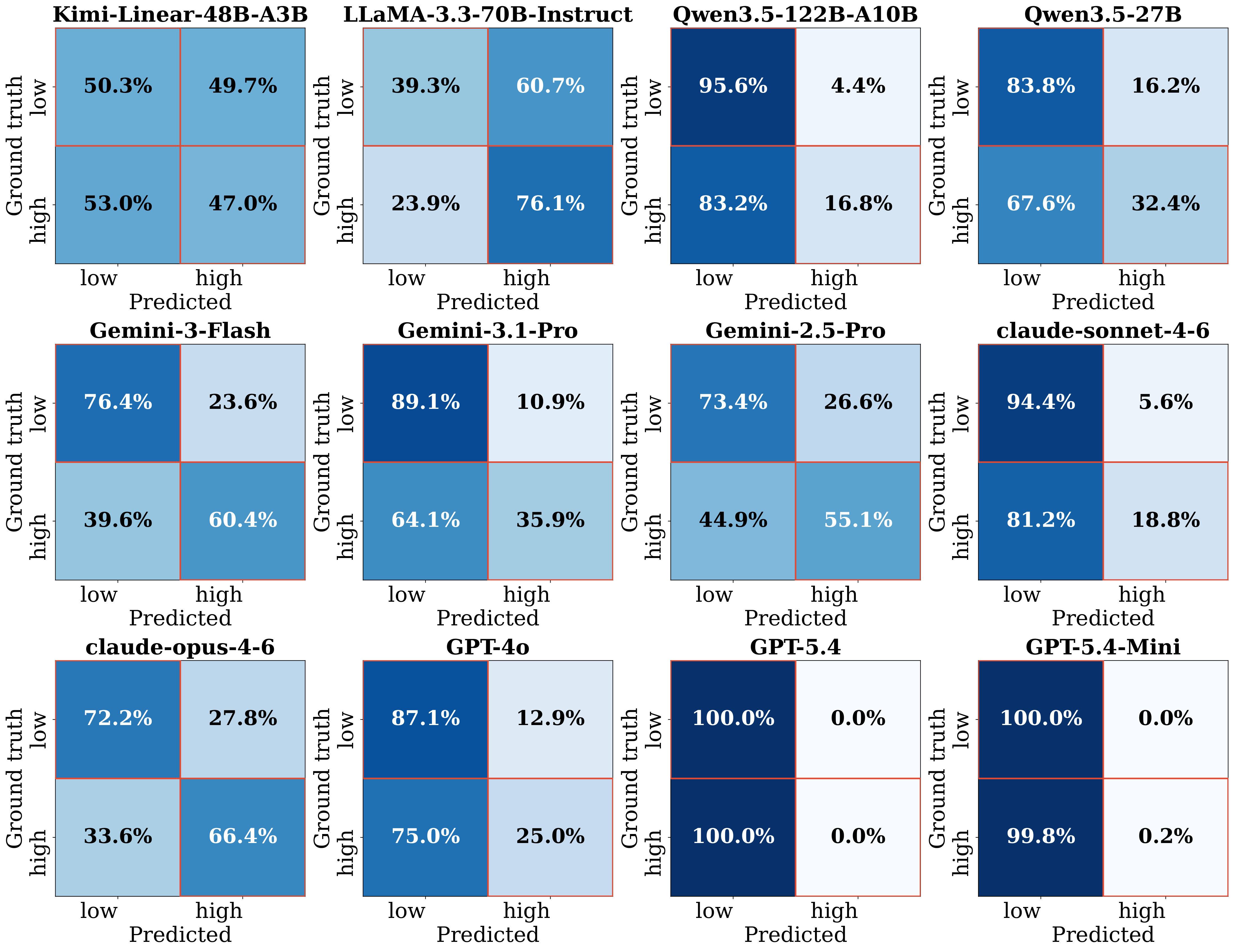
than exact prediction of full-paper review outcomes. Across 12 frontier LLMs, we find a pervasive
optimism bias: under standard prompting, models frequently rate low-soundness proposals as
sound, while aggressive prompting largely shifts errors from false positives to false negatives. Additional
controls for public-corpus contamination, paper-identifying phrases, surface features, and human audit quality
suggest that this behavior is not explained by a single confounder. Our results indicate that current LLMs are
not yet reliable as standalone first-gate evaluators for scientific rigor.